Upstream Personalization & Optimization for Product & Communication Resonance
Personalization of products and messaging is a key goal for many of today’s marketers. According to an Epsilon report, 80% of customers are more likely to do business with a company if it offers a personalized experience. Billions of dollars are being spent downstream to apply analytics to big data for campaigns or product launches in an effort to optimize personalized messages.
But optimization of personalized products, services, or communications can and should begin earlier in the process. Optimizing upstream before launch or before entering a market will make the most of the resources spent identifying and understanding audiences and obtaining information on how to activate them.
The next generation of agile market research—happening now—can help brands obtain information, relevant to personalization, that is both strategic and tactical much sooner. Agile market research makes it easier for brands to understand their audiences more holistically and in ways that are more directly relevant to in-market activation. The key? Being intentional in how we deliver strategic audience insights quickly and at lower cost by connecting and combining survey and non-survey data.
To understand what we mean by this, let’s start by reviewing the original 4 V’s classification for big data:
- Velocity or the speed and frequency of data
- Volume or the amount and size of data
- Variety or the diversity of types/formats of data
- Veracity or the degree of (un)certainty about data
In general, survey data is slower and smaller than non-survey or big data and survey data has a structured format, whereas non-survey data can be structured or unstructured. But unlike big data, the veracity of survey data under various scenarios is relatively well-known. Yes, survey responses can suffer from poor recall or other errors, but we know a lot about how to avoid making major mistakes when using survey data—which is currently unknown for many big data sources.
Changing the Perspective
As market researchers, we can offer brands more valuable support for their personalization efforts by conducting research that links and combines data big and small—the what and the why—in agile ways to help clients advance their personalization and other strategic objectives. By doing so, we can help brands to go beyond the 4 V’s to achieve the often talked about but less often fully realized V—value.
To achieve the highest value, we need to change our perspective on how to harness big data to its maximum advantage. The new approach we need is shown in the second column of the table below. We can advance personalization and other strategic objectives by delivering amplified, scalable, confident insights about activation-ready audiences—including audiences we identify in the moment as we conduct pre-market and pre-launch research.
Easier said than done, you say? Here is an example that illustrates this new perspective in action.
A Case Study: In-the-Moment Audience Creation
A client with a new beverage product wanted to identify and understand the group of consumers with the highest potential to try their new product. By doing so, they could develop a personalized creative brief and move confidently toward in-store and media activation with resonance for these potential early triers.
We presented our client’s finished, winning concept to survey respondents and, in the moment, identified the subset of beverage drinkers with the highest likelihood of trying the new product. In addition, we used tags to link this group of concept acceptors to third party data. Doing so allowed for deeper profiling without asking additional survey questions and set the stage for our client to reach their target consumers using digital targeting.
Identifying and understanding these dynamically created, activation-ready audiences further upstream increases the speed at which personalization optimization occurs.
Scalable Insights
There are market research vendors as well as traditional data brokers, like Acxiom and Experian, who can append additional data from big data sources to a set of freshly collected survey responses. After additional data are appended, the enriched dataset is typically provided back to the company that requested it, where they conduct analysis and extract insights from it.
Unfortunately, the process of appending big data to a sample and then analyzing the enriched sample abstracts the big data away from its context. In short, the append to enrich a sample process makes big data small—as small as the sample to which the data is appended to.
We recommend reversing the process. We append survey data to third party big data and examine the overlap between the sample and the big data. By conducting the analysis within the context of the big data universe we scale our audience insights to the larger population. Even in relatively small samples of survey respondents, we can confidently conclude that an audience over-indexes on traits X or Y because we can see the signal break through in the linked big and small data.
Figure 1, below, shows an example of indexing big data to obtain results for the portion of our beverage client’s concept favorable audience. Notice in this specific example that we have also been able to classify personality motivators for this audience at scale without asking any additional survey questions.

Another Case Study: Amplifying Insights
In another study, we conducted in the yogurt category, we segmented consumers to identify in the moment the audience most likely to switch away from competitor brands to our client’s brand. We then overlaid this information about the size of the switcher audience on big data measuring actual past-12-month purchasing of competitor brands in the grocery channel.
Combining both types of data yields a new metric that we call the Minimum Opportunity in Grocery (MOG) that tells us our client brand has the potential to acquire 3.13 million customers from its competitors. By using both sources of data we are able to amplify the big data to obtain a specific estimate of the number of buyers who are likely to switch.
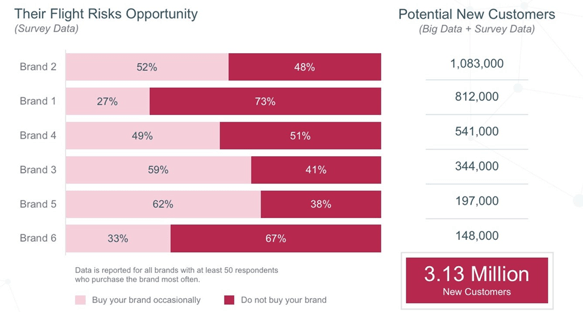
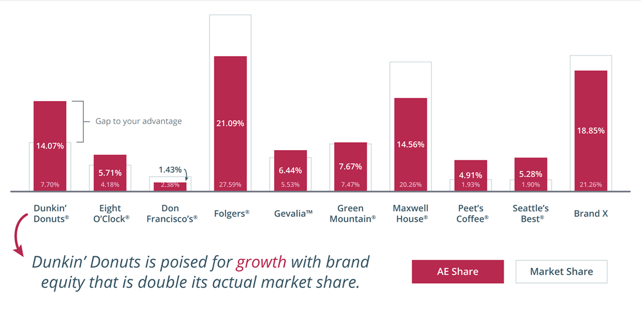
In a second example of amplified insights, we juxtaposed a survey-based measure of attitudinal equity—the percentage of hearts and minds captured by each brand—with a non-survey based measure of behavioral loyalty—market share based on actual purchase behavior for the grocery channel.
Combining both types of data gives us the buy plus why and yields another new metric—the gap between the percentage of hearts and minds and actual market share—which provides stronger and more actionable insights than either would provide by themselves. By using both data sources we get amplified strategic insights that neither source alone can provide.
Confident Insights
In the example above, the big data for actual past-12-month purchasing behavior is based on loyalty card transactions from some, but not all US retailers. The degree to which this loyalty card data is representative is an unknown aspect of its data veracity.
So to resolve that concern, we included a question in the survey asking category purchasers to tell us how many of their last 10 purchases had been of different brands in the category so we could compute a proxy for purchasing behavior based on self-reported information from a sample that we know was balanced to be representative for age, gender, and region.
We compared this survey-based proxy and actual purchase data to see if they exhibited a similar pattern of market share across brands (e.g., the market leader was the same and relative proportions were similar). Because the answer was yes, we can confidently analyze the big data having removed an important piece of uncertainty about its veracity.
Be More Intentional
While it might not be obvious, to achieve scalable, amplified, confident, in-the-moment insights requires that we design our research differently. We need to stop thinking about surveys as all-purpose instruments for data collection and instead design surveys so that they contain questions that can fill the gaps in big data—combined with big data, we get new, more powerful metrics, and verify and improve the veracity of big data sources.
And most importantly, we need to design research with an intentional focus on identifying, understanding, and tagging new activation-ready audiences to jump start and improve personalization long before any product or campaign launches. Only then will we ensure our clients receive the most important V—value.
Written By

Renee Smith
Chief Research Officer
Want to stay up to date latest GutCheck blog posts?
Follow us on
Check Out Our Most Recent Blog Posts

When Vocation and Avocation Collide
At GutCheck, we have four brand pillars upon which we build our business. One of those is to 'lead...

Reflections on Season 1 of Gutsiest Brands
Understanding people is at the heart of market research. Sure, companies want to know what ideas...

Permission to Evolve with Miguel Garcia Castillo
(highlights from Episode #22 of the Gutsiest Brands podcast) Check out the latest lessons from our...
1-877-990-8111
[email protected]
© 2023 GutCheck is a registered trademark of Brainyak, Inc. All rights reserved.
© 2020 GutCheck is a registered trademark of Brainyak, Inc. All rights reserved.