Veracity: The Most Important “V” of Big Data
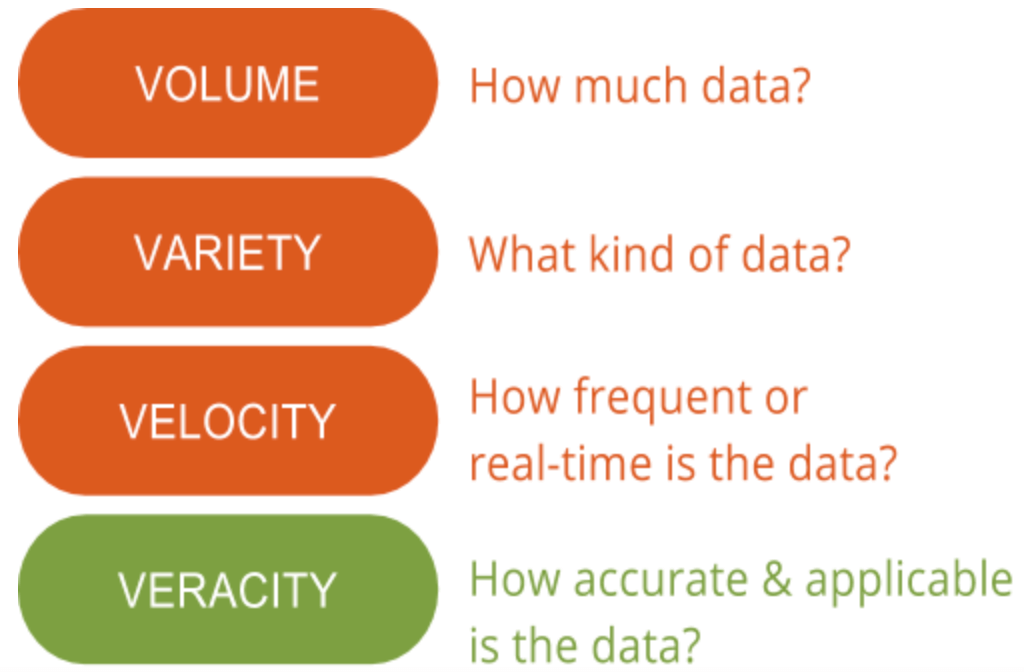
Here at GutCheck, we talk a lot about the 4 V’s of Big Data: volume, variety, velocity, and veracity. There is one “V” that we stress the importance of over all the others—veracity. Data veracity is the one area that still has the potential for improvement and poses the biggest challenge when it comes to big data. With so much data available, ensuring it’s relevant and of high quality is the difference between those successfully using big data and those who are struggling to understand it.
 Understanding the importance of data veracity is the first step in discerning the signal from the noise when it comes to big data. In other words, veracity helps to filter through what is important and what is not, and in the end, it generates a deeper understanding of data and how to contextualize it in order to take action.
Understanding the importance of data veracity is the first step in discerning the signal from the noise when it comes to big data. In other words, veracity helps to filter through what is important and what is not, and in the end, it generates a deeper understanding of data and how to contextualize it in order to take action.
What Is Data Veracity?
Data veracity, in general, is how accurate or truthful a data set may be. In the context of big data, however, it takes on a bit more meaning. More specifically, when it comes to the accuracy of big data, it’s not just the quality of the data itself but how trustworthy the data source, type, and processing of it is. Removing things like bias, abnormalities or inconsistencies, duplication, and volatility are just a few aspects that factor into improving the accuracy of big data.
Unfortunately, sometimes volatility isn’t within our control. The volatility, sometimes referred to as another “V” of big data, is the rate of change and lifetime of the data. An example of highly volatile data includes social media, where sentiments and trending topics change quickly and often. Less volatile data would look something more like weather trends that change less frequently and are easier to predict and track.
The second side of data veracity entails ensuring the processing method of the actual data makes sense based on business needs and the output is pertinent to objectives. Obviously, this is especially important when incorporating primary market research with big data. Interpreting big data in the right way ensures results are relevant and actionable. Further, access to big data means you could spend months sorting through information without focus and a without a method of identifying what data points are relevant. As a result, data should be analyzed in a timely manner, as is difficult with big data, otherwise the insights would fail to be useful.
Why It’s Important
Big data is highly complex, and as a result, the means for understanding and interpreting it are still being fully conceptualized. While many think machine learning will have a large use for big data analysis, statistical methods are still needed in order to ensure data quality and practical application of big data for market researchers. For example, you wouldn’t download an industry report off the internet and use it to take action. Instead you’d likely validate it or use it to inform additional research before formulating your own findings. Big data is no different; you cannot take big data as it is without validating or explaining it. But unlike most market research practices, big data does not have a strong foundation with statistics.
That’s why we’ve spent time understanding data management platforms and big data in order to continue to pioneer methods that integrate, aggregate, and interpret data with research-grade precision like the tried-and-true methods we are used to. Part of these methods includes indexing and cleaning the data, in addition to using primary data to help lend more context and maintain the veracity of insights.
Many organizations can’t spend all the time needed to truly discern whether a big data source and method of processing upholds a high level of veracity. Working with a partner who has a grasp on the foundation for big data in market research can help. To learn about how a client of ours leveraged insights based on survey and behavioral (big) data, take a look at the case study below. You’ll also see how they were able to connect the dots and unlock the power of audience intelligence to drive a better consumer segmentation strategy.
Learn how GutCheck’s Persona Connector solution leverages a combination of survey and big data to bring actionability to persona development.
Follow us on
Check Out Our Most Recent Blog Posts

When Vocation and Avocation Collide
At GutCheck, we have four brand pillars upon which we build our business. One of those is to 'lead...

Reflections on Season 1 of Gutsiest Brands
Understanding people is at the heart of market research. Sure, companies want to know what ideas...

Permission to Evolve with Miguel Garcia Castillo
(highlights from Episode #22 of the Gutsiest Brands podcast) Check out the latest lessons from our...
1-877-990-8111
[email protected]
© 2023 GutCheck is a registered trademark of Brainyak, Inc. All rights reserved.
© 2020 GutCheck is a registered trademark of Brainyak, Inc. All rights reserved.